深度 | 听!具备深度学习能力的助听器是怎么工作的?
信息来源:爱耳时代 时间:2017-01-11

本文经机器之心(almosthuman2014)授权转载,禁止二次转载
选自IEEE Spectrum
作者:汪德亮
机器之心编译
参与:Jane W、杨旋、吴攀

本文作者汪德亮(DeLiang Wang)是美国俄亥俄州立大学教授、感知与神经动力学实验室的主任、IEEE Fellow。主要致力于机器感知和信号处理领域的研究,在听视觉处理的神经计算研究方面也取得了重大成果。
当我离开家去上大学时,我的母亲开始失去她的听力。我回家分享我学到的东西,她会侧身倾听。很快发展到如果同时有多人说话她将很难与人对话。现在,即使有了助听器,她仍然需要努力分辨每句话的声音。当我的家人来用晚餐时,她仍然央求我们轮流和她说话。
我母亲的艰难处境也是助听器制造商所面临的一个经典问题。人类听觉系统能自然地在嘈杂的房间中分辨声音,但是制造一个能模仿这种能力的助听器困扰了信号处理专家、人工智能专家和听力学家数十年。1953 年,英国认知科学家 Colin Cherry 首次将这称为「鸡尾酒会问题(cocktail party problem)」。
六十多年后,在需要助听器的人群中,只有不到 25%的人真正使用了助听器。令这些潜在用户犹豫的最大问题是助听器并不能区分同时发生的声音,如人的语音和经过的汽车的声音。助听器同时将两者音量放大,产生令人疑惑的音调。
现在是我们解决这个问题的时候了。为了给助听器佩戴者提供更好的体验,最近,在哥伦布市的俄亥俄州立大学的实验室将基于深度神经网络的机器学习应用到了分离声音的任务了。我们测试了多个版本的数字滤波器,它们不仅可以放大声音,还可以隔离背景噪声和自动调整每种声音的音量。
我们相信这种方法最终可以恢复听力受损的人的理解能力,以达到甚至超过正常人的听力。事实上,我们的一个早期模型将受试者理解被噪声掩盖的语音单词的能力从 10%提高到 90%。因为听者理解含义不需要听清短语中的每个单词,这种改进通常意味着能否成功能理解一个句子。
没有良好的助听器,听损者的听力将无法得到保障。世界卫生组织估计,有 15%的成年人(或大约 7.66 亿人)可能有听力受损。随着人口增长,这一数字还将继续增大;而且在成年人群中,年纪越大的人听力受损者所占的比例也越大。同时先进助听器的潜在市场不仅仅限于有听力受损的人。开发人员可以使用该技术来改进智能手机的语音识别功能。雇主们可以帮助工人降低嘈杂的工厂车间带来的噪音,军队可以为士兵们装备设备使他们能够在战争的混乱中听到彼此。
这一切都是巨大的潜在市场。根据在印度浦那市的市场研究公司 MarketsandMarkets 统计,现今 60 亿美元的全球助听器产业预计将以 6%的年增长率增长,这一趋势将持续到 2020 年。但是要满足所有新客户的要求,这意味着要寻找到一个能够解决鸡尾酒会问题的万全解决方法。终于,深度神经网络为前进的道路指明了方向。
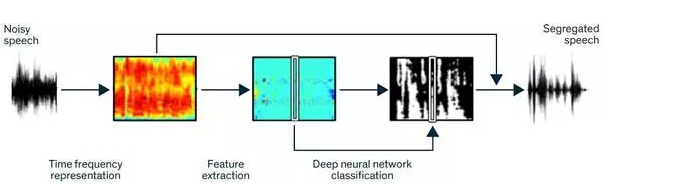
Clean Speech:为了将语音与噪声分离,机器学习程序将嘈杂的语音样本分解成被称作时频单元(time-frequency unit)的元素集合。下一步,它分析这些单元来提取区分语音与其它声音的 85 个特征。然后,该程序将特征传入经过训练的深度神经网络中,基于相似样本学习的经验,这个网络能够区分时频单元是否为语音。最后,该程序使用数字滤波器来过滤所有非语音单元,仅分离保留语音部分。
几十年来,电气和计算机工程师尝试通过信号处理实现语音分离,但是均以失败告终。最流行的方法是使用语音活动检测器(voice-activity detector)来识别人语音间的间隙。在该方法中,系统把那些间隙中捕获的声音指定为「噪音」。然后,算法从原始记录中减去噪声,在理想状态下可以留下无噪声的语音。
不幸的是,这种称为谱减法(spectral subtraction)的语音增强算法是不理想的,它要么会去除过多的语音,要么只去除微量的噪音。往往结果是一段不悦耳的合成音(称为音乐噪声(musical noise)),使音频听起来好像是在水下录制的。该问题是如此严重,以至于经过多年的发展,这种方法仍无法提高人们在嘈杂环境中识别语音的能力。
我意识到我们必须采取不同的方法。我们从加拿大蒙特利尔麦吉尔大学心理学家 Albert Bregman 的一个理论开始,他在 1990 年提出人类听觉系统将声音组织成不同的流(stream)。一条流本质上对应一个源(如附近朋友)发出的声音。每个声音流在音高、音量和方向都是独特的。
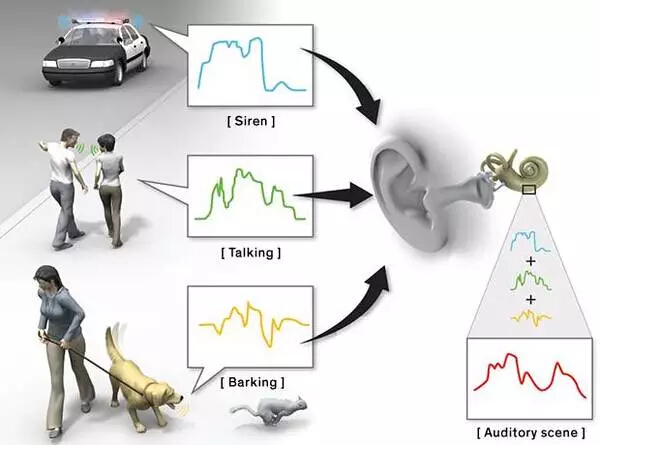
嘈杂的世界:人类的耳朵能一次捕获许多声音流,部分归功于其特殊的形状。一条流是指从单个源(如狗)发出的所有声波。所有流组合在一起,就构成了一个听觉场景(吠叫+警报+说话)。
许多流放在一起——如曲棍球比赛的呐喊声中朋友的说话——构成了 Bregman 所谓的「听觉场景(auditory scene)」。如果同时有在相同频带(frequency band)的声音,那么场景中最响亮的声音会超过其它声音,这种原理称为听觉掩蔽(auditory masking)。例如,如果屋顶上有下雨的声音,人们可能就不会注意到房间角落时钟的滴答声。这个原理和其它一些原理已经被应用到了 MP3 文件压缩技术上——能使文件大小压缩到原始大小的十分之一——它的原理是消除被掩蔽的声音(如滴答作响的时钟)而不被用户注意到。
回想 Bregman 的研究,我们想知道是否可以构建一个滤波器来确定一个声音流在特定频带内的某一时刻是否支配其它声音流。研究声音感知(sound perception)的心理声学家(Psychoacoustician)将人类听力范围平均划分为 20 赫兹至 20000 赫兹间的 20 多个频带。我们想要滤波器来告诉我们在某时刻这些频带内的包含语音或噪声的声音流哪个更强,这是分离两者的第一步。
2001 年,我的实验室是第一个设计这种滤波器的实验室,它将声音流标记为语音或噪音。我们可以基于一些区别特征(如振幅(响度)、谐波结构(音调的特定排列)和开始(onset)(特定声音开始的时间))在滤波器上开发机器学习程序,用来区别语音和其它声音。
这个原始的滤波器是理想的二进制掩码(binary mask)。它在称为时频单元的声音段中标记语音和噪音,时频单元用来指定特定频带内的特定短暂间隔。滤波器分析嘈杂语音样本中的每个时频单元,并将每个标记为 1 或 0。如果「目标」声音(语音)比噪声更大,则记录 1,如果目标声音比噪声小,则记录 0。结果是 1 和 0 的集合,用来表示样本内噪声或语音哪个占主导地位。然后,滤波器删除所有标记为 0 的单元,并将那些得分为 1 的单元重新组合成语音。为了能从有噪声的音频中挑出语音并重新组合成可理解的句子,必须将一定百分比的时频单元标记为 1。
我们于 2006 年与俄亥俄州的美国空军研究实验室(U.S. Air Force Research Laboratory)合作测试理想的二进制掩码。大约在同一时间,来自纽约雪城大学的一个团队独立评估了理想的二进制掩码。在这些试验中,滤波器能帮助患有听力障碍的人以及具有正常听力的听众更好地理解混合噪声的语句。
从基础上说,我们创建了一个实验室环境下完美无瑕的语音滤波器。但这个滤波器的优势在现实中并不成立。设计上,我们分别提供了语音和噪声的样本训练,然后用混合的相同样本进行测试。因为它已知答案(这就是为什么它被称为「理想」),滤波器知道什么时候语音比背景噪声更强。一个实际工作的滤波器必须完全靠自己、一边听一边处理地将一个空间中的噪声和语音分离开。

照片拍摄于 2013 年,一个基于深度神经网络的语音分离机器学习程序正由俄亥俄州立大学的(从左到右)Sarah Yoho、DeLiang Wang、Eric Healy 和 Yuxuan Wang 测试。
不管怎样,对于听力受损的听众和具有正常听力的人来说,理想的二进制掩码显著地改善了他们的语音理解能力,这具有深刻的意义。它表现了可学习的分类技术,作为一种分离语音和噪声的方式,可以用来近似理想的二进制掩码。实际上,通过完成练习、接收反馈、绘制和从经验吸取教训,机器以分类的方式模仿人类学习。这本质上就是人类幼年学习将苹果区分于橘子的过程。
在接下来的几年中,我的实验室第一次尝试通过分类近似理想的二进制掩码。大约在我们开发原始分类器的同一时间,在匹兹堡的卡内基梅隆大学的一个小组也在通过机器学习算法分类时频单元,但他们的目的不同:提高自动语音识别。后来,德克萨斯大学达拉斯分校的一个由 Philipos Loizou 领导的小组使用了一个不同的分类方法,成为第一个为依靠单耳(相对于双耳)具有正常听力的人改善语言清晰度的团队。
但是这些早期的机器学习分类技术的准确度还不够高,能给助听器佩戴者提供的帮助还不够多。它们还不能处理一些比较复杂和不可预知的问题,不能把噪音和有效语音分离。为了达成这个目的,我们需要一些更强大的东西。
我们在我们早期的分类算法的执行结果中看到了前景,我们决定采取下一个逻辑步骤来改进系统,让其在没有训练特定的噪声和句子的情况下也可以在嘈杂的真实环境中工作。正是这些具有挑战的事情促使我们尝试去做一些以前从未做过的事情:构建一个运行在神经网络上的机器学习程序(参考论文《An algorithm to improve speech recognition in noise for hearing-impaired listeners》),让其在经历复杂的训练过程之后可以将语音与噪声分离。程序将使用理想的二进制掩码来指导神经网络的训练。最后,我们成功做到了。在一项涉及 24 名测试对象的研究中,我们证明了该程序可以将听力障碍人士的理解程度提高约 50%。
从根本上说,神经网络是由一些相对简单的元素构成的软件系统,这些简单的元素聚合在一起就可以处理一些较复杂的问题。(这个系统的架构大致上是在模仿大脑中的神经元的工作)当遇到新的问题的时候,神经网络就会像人类大脑一样,通过调整各个神经元之间连接的权重来进行「学习」。
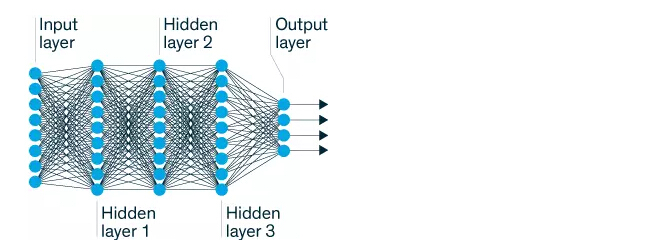
Smart Layers:深度神经网络的输入输出层之间有两个或两个以上的处理层,输入信息被输入到输入层(左),然后这些信息经过处理层的处理之后又被送到了输出层(右),这就是我们需要的结果。研究人员可以通过调整系统的参数和各个层之间的连接来提高系统的性能。
神经网络具有很多种不同的形状和规模,并且它们的复杂度也各不相同。深层神经网络被定义为具有至少两个「隐藏」处理层,并且它们不直接和系统的输入输出层进行连接。每个隐藏层都会对前一层传递给它的内容进行优化,基于现有知识再添加一些新的考虑。
举个例子,有一个用于识别客户手写体签名的程序(参考论文《Machine Learning for Signature Verification》),这个程序一开始会把新的签名和训练数据库中已经存在的签名进行对比。当然,经过训练后这个程序知道是不需要要求新的签名和原始签名必须完全匹配。其他层可以确定这个新签名和原始签名在某些特征上是否是保持一致的,比如字体的倾斜的角度或者是字母 i 上面的那一点的缺失。
为了建立我们自己的深度神经网络,我们开始通过编写算法来提取一些特征,这些特征通过声音的振幅、频率和各个调制的变化来从噪声中提取有用的语音。我们选定了几十个特征,这些特征可以在一定程度上帮助我们的程序区分语音和噪声,我们使用了所有选定的这 85 个特征,希望可以使算法尽可能地强大。在我们所选定的这些属性中,最重要的是声音的频率和它们的振幅(声音大或者小)。
接下来,我们使用了这 85 个选定的特征来训练深度神经网以实现区分语音和噪声的目的。这个训练过程一共有两个阶段:第一阶段,我们通过无监督学习设置程序的参数。也就是说,为了让我们程序可以在以后运行的过程中把各种各样的输入信号进行分类,我们会将许多属性的样例集加载到程序中。
接下来是第二阶段的训练,我们将使用嘈杂的语音和我们所期望得到的分类结果的二进制掩码作为训练样本,这个过程是监督学习。其中,构成理想结果的二进制掩码的 1 和 0 的集合就像一个答案表,我们用它来测试并提高我们的程序分离语音和噪声的能力。对于每个新样本,程序将从嘈杂的语音中提取一组属性。然后,程序会对语音的频率、振幅等属性进行分析,在这之后滤波器会执行一个暂时的分类以确定这到底是有效语音还是噪音,接下来会把这个分类的结果和样例中的分类结果进行对比。如果这个结果与我们所期望得到的 01 序列不匹配,我们就会调整神经网络中相应的参数,以便网络在下一次运行的时候可以产生更接近理想二进制掩码的 01 序列结果。
为了进行这些调整,我们首先会计算神经网络的误差,即对比理想二进制掩码和神经网络的最后一层(输出层)的输出结果之间的差异。当我们计算出误差以后,我们将使用它来改变神经网络各连接的权重,使得如果再次执行相同的分类,误差可以减小。为了减小误差,神经网络会对这个过程进行成千上万次的迭代。
为了对整个系统进行进一步的改进,我们在第一个神经网络之后构建了第二个深度神经网络,第一个神经网络的输出会作为第二个神经网络的输入。第一个神经网络着重于在每个独立时间 - 频率单元内对属性进行标记,第二个网络将会检查特定单元周围的几个单元的属性。我们用一个比喻来说明这样做为什么会有帮助:假设我们正在购买房屋,如果把第一个网络比喻成房子的房间,那么第二个网络就像周围的社区。换句话说,第二网络向第一网络提供了关于它处理的语音和噪声的额外的上下文环境,并且进一步提高了其分类的精度。例如,音节可以跨越许多时间-频率单元,但是背景噪声可以在说话时突然改变。在这种情况下,上下文线索可以帮助程序更准确地分离语音和音节内的噪声。
在监督训练的最后阶段,深度神经网络分类器被证明远远优于那些早期的用于分离语音与噪声方法。事实上,对于任何依赖于单声道技术来帮助听觉有障碍的人去理解那些被噪声所掩盖的语音中的信息的技术而言,算法都是十分重要的。
为了在人类身上做测试,我们邀请了 12 名听力障碍人士和 12 名正常听力人士通过耳机收听嘈杂句子中的样本。每个样本都是一对组合;首先会同时播放语音和噪声,然后我们将使用我们的深度神经网络程序对相同的样本进行处理后再播放。这些样本会包括诸如「这个地方变冷了」和「他们吃了柠檬饼干」等句子,同时这些句子会被混杂在两种类型的噪音之中:一种是稳定的嗡嗡声和另一种是许多人同时说话的声音。稳定噪声类似于冰箱运行的声音,其音频波会一直重复,并且频谱的形状不会随着时间改变。我们增加了来自四个男性和四个女性的谈话声来模仿鸡尾酒宴会,创造了第二种嘈杂的背景声。
在使用我们的程序对句子处理之后,两组受试者在噪声中理解句子的能力都有了显着改善(参考论文《An algorithm to improve speech recognition in noise for hearing-impaired listeners》)。在对声音样本进行处理之前,有听力障碍的人可以听懂其中 29%的词,对声音处理之后,它们可以理解 84%的词了。在这其中还有几个人一开始只能理解原始样本中 10% 的词,对样本进行处理后他们可以理解大约 90%的词。在稳定噪声的情况下进行测试也有类似的增益,他们能理解的词从 36% 提升到了 82%。
对于听力正常的人,我们的程序也能帮助他们更好地理解嘈杂环境中的句子,这意味着我们的程序将来可以帮助到比我们预期更多的人。具有正常听力的听众在稳定噪声中只能理解 37% 的词,在我们程序的帮助下他们可以理解 80% 的词了。在混乱噪声的情况下,他们能理解的词也从 42% 提升到了 78%。
我们实验的最有趣的结果之一是,在我们的程序的帮助下,听力障碍的人可以比正常听力的人的理解能力提升更多吗?显然,这个答案是肯定的。有听力障碍的听众使用我们的程序之后,比单纯依靠自己的听觉系统分离语音和噪音的正常听力者在嘈杂噪声和稳定噪声中分别多理解了 20% 和 15% 的词。由这个结果可得,在各种鸡尾酒宴会问题的解决方案中,我们使用深度神经网络构建的程序取得了迄今为止最优的结果。
当然,程序的能力是有限的。例如,在我们的样本中,我们所使用的噪声样本与程序已经训练分类的噪声类型非常相似。为了让我们的程序在现实生活中起作用,程序需要快速的去学习并过滤掉多种类型的噪声,其中包括包括那些还没有遇到过的类型。例如,通风系统的嘶嘶声就与冰箱压缩机的嗡嗡声不同。此外,我们使用的噪音样本没有混合房间的墙壁和物体的声响,如果加入这些噪音将会使任何的鸡尾酒会噪声问题更加复杂。
在我们发布这些早期的结果之后,我们又购买了一个电影制作人设计的声音效果数据库,并使用了 10,000 个声音进一步地训练我们的程序。今年,我们发现经过再次训练的程序对于全新的噪音也可以提高听力受损听众和正常听众的理解能力了(参考论文《Large-scale training to increase speech intelligibility for hearing-impaired listeners in novel noises》)。现在,通过国家耳聋及其他交流障碍研究所(National Institute on Deafness and Other Communication Disorders)的资助,我们正在推动该计划在更多的环境中运行,并对更多的听力障碍者进行测试。
最终,我们相信我们的程序在拥有强大的计算性能的计算机上进行训练后,可以直接被嵌入助听器,或通过无线链路(如蓝牙)与智能手机配对,可以将处理的信号实时的传送到耳机中。助听器佩戴者也可以定期地更新他们的设备,因为制造商会对系统进行新噪声的训练,之后会发布新版本。我们已经为该技术提交了多项专利,并与合作伙伴一起对其进行了商业化。
有了这种方法,鸡尾酒会问题看起来不像几年前那样令人生畏了。我们期望最终可以通过制造在更嘈杂的情况下进行更广泛的培训的软件来克服它。事实上,我怀疑这个过程和孩子们在生活中学习对噪声和语音的分离方式类似,他们通过反复接触大量的噪声和语音来学习。随着拥有越来越多的经验,这种方法会变得更好。这就是它吸引人的地方。对于年轻人而言,也是这个道理,时间是由我们自己掌控的。
— END —

