大脑控制助听器来了!AI与AAD合体,想听哪里听哪里!
信息来源:爱耳时代 时间:2017-08-09

据英国《每日邮报》8月4日报道,哥伦比亚大学工程研究所正在研制一款由大脑控制的助听器技术,其中研究人员利用听觉注意力解码技术和AI,实现了用大脑的认知信号来控制助听器对外界声音的主观选择。简单来说,就是该技术可以让佩戴者用大脑来控制助听器。

据报道,这项属于未来科技的研究由哥伦比亚大学电机工程副教授Nima Mesgarani领导,并由哥伦比亚大学医学中心神经外科和Hofstra-Northwell医学院、费恩斯坦医学研究所合作完成。
这项研究并非空穴来风,而是建立在已知成熟的科学研究成果上,听觉注意力解码(AAD)技术和AI(深度学习)是实现这一目标的两大基础。这项技术的原理是通过拾取大脑的神经信号来获取其注意力目标,从而判断出注意力方向。
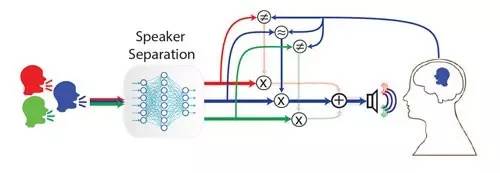
目前,市场上现有的助听器已经可以有效过滤背景噪声,但无法识别并放大使用者想要单独听到的声音,这一直是数字助听器的研究瓶颈之一。而新的助听器认知技术可以通过监测佩戴者的大脑活动,在嘈杂的背景声中分辨出他们想要听的那个声音并将其放大。
用通俗的话来说,这种技术可以在佩戴助听器的同时,实时监测使用者大脑活动,以确保使用者在嘈杂环境下可以与自己想要交流的对象轻松交谈。
这项工作结合了两门学科的最新技术——声学工程和听觉注意力解码。我们只要加入深层神经网络模型来帮助自动分离语音信号,整个系统就可以运用起来。
—— Nima Mesgarani
早前,团队就有利用人的认知意识来控制助听器的想法,直到2012年,他们通过侵入式方式记录了神经信号,随后实现对神经信号的解码,获取被测试者注意力的目标。后来,在2015年,他们表示可以通过非侵入性方法实现AAD技术。
不过整个研发过程并非易事,对此,与Mesgarani一起工作的博士后科学家James O'Sullivan指出,将科学上的发现转化为现实世界的可操作技术需要历经成百上千次实验。
在听觉注意力解码的实际操作中,研究人员就面临扬声器种类选择问题。于是他们通过将受试者脑部的神经反应记录与不同种类扬声器发出的语音信号进行比较,得出与神经数据最大相似性的扬声器。事实证明,该系统只能采用全频扬声器,而非单频扬声器。
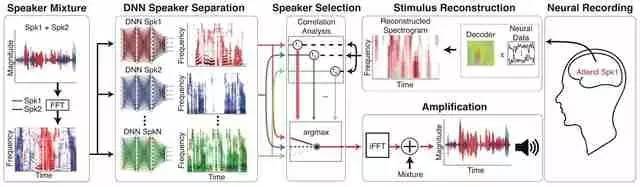
最终,Mesgarani的团队开发了一个端对端系统,这个系统会根据使用者神经信号的解码信号选定到特定的音频接收通道,其中每个通道都包含一个全频扬声器。随后该系统会自动分离全频扬声器中的声音信号,确定使用者关注的声音信号,然后放大该信号,确保使用者能够清晰听见。该团队使用癫痫手术的神经学受试者的侵入性电皮质记录测试了该系统的功效。
在测试中,他们确定了对AAD有贡献的听觉皮质区域,发现该系统仅使用混频就可以解码使用者的注意力方向,并能够放大他或她想要听的声音。并且值得注意的是,整个过程的执行最多只要十秒。

基于脑波信号来处理大量的音频数据和神经解码信号是该助听器系统的重要功能,无疑,实时进行这样的操作需要超强的计算能力,而将强大的处理器缩小到标准助听器的大小是十分艰难的。
幸运的是,材料科学的进步使得这样的微型计算机成为可能。对此,Mesgarani表示,目前正在进行大量的研究,以制造小型专用芯片,满足所需的计算。
此外,他还表示,因为使用了深层神经网络,且有硬件的支持,最新的助听器数据可同步到手机等设备上,这将有助于在这种小型设备中进行大量计算。
据了解,该技术目前还处于早期的概念验证阶段,但Mesgarani说,如果一切顺利,五年内,这一技术将开始在商业助听器中出现。
— END —

